Articles & Blogs
You Rated Yourself Excellent. The Agents Didn't.
A new Deloitte Digital study surveyed both sides of the counter and found a wide gap: brands believe they deliver good commerce experiences, and...
Catalog Scoring gives every product a 0–100 readiness score for AI shopping agents across seven dimensions, and shows exactly which gap to fix first.

Your customers are increasingly not searching your site. They're asking an AI agent – ChatGPT, Gemini, Copilot – to find the right product for them. And when an agent goes looking, it doesn't read your product page the way a person does. It reads your product data. Whether your product gets surfaced and recommended comes down to one question: is that data good enough?
Until now, that question never had a real answer. As a retailer/brand, you could open an SKU, look at the product-page, and form an opinion, but "good enough" was a judgment call. Enrichment work got prioritized by gut feel, and there was no clean way to show a leadership team whether last quarter's data cleanup actually made products more discoverable.
Catalog Scoring fixes that. It gives every product a single 0–100 score for how ready its data is to be recommended by AI shopping agents, and tells you exactly which gap to close first.
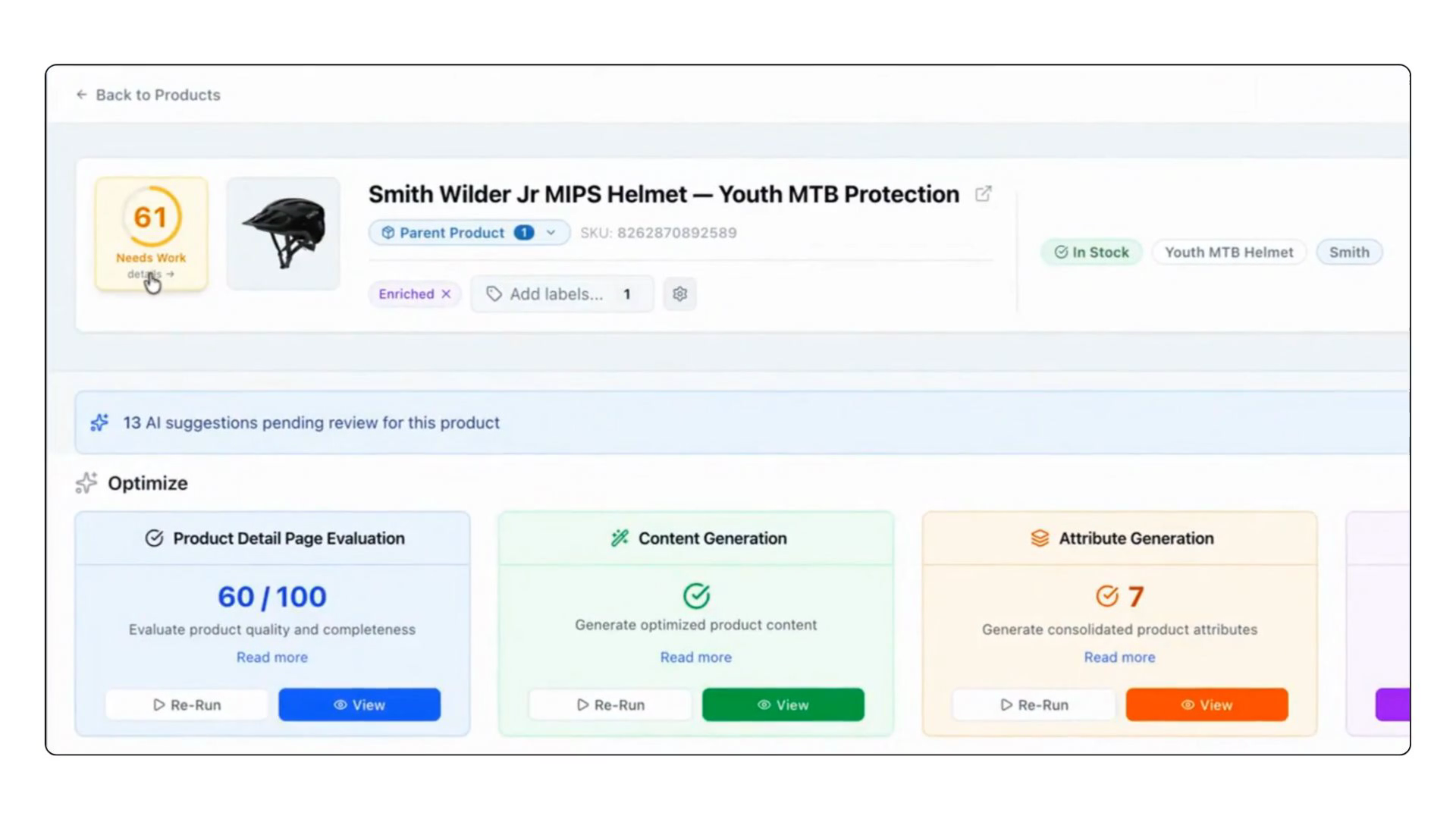
Catalog Scoring evaluates each product's data the way an AI shopping agent would encounter it: your source data plus any enrichments you've accepted, the exact payload that would reach an agent. It grades that payload across seven weighted dimensions:
Each dimension is scored 0–3 and carries a fixed weight. The overall score is the weighted total, scaled to 0–100 and mapped to a readiness band: Excellent (85+), Good (65–84), Minimal (40–64), and Deficient (below 40).
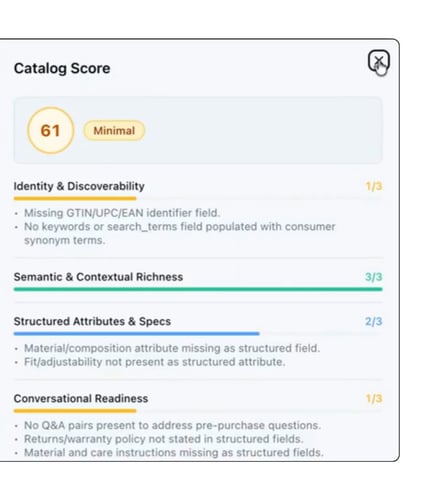
It's tempting to ask for a separate "ChatGPT score" and "Gemini score." We deliberately didn't build it that way, because ChatGPT, Gemini, and Copilot all want the same thing: product data that's complete, structured, and clear enough to recommend with confidence. One readiness score, fixed once, makes a product readier everywhere. That's a stronger position than chasing each engine's quirks separately.
A score on its own is a report card. What makes Catalog Scoring useful is what sits underneath it. Open any product's score detail and you'll see, per dimension, the specific gaps found — "no structured specs," "no Q&A covering compatibility or returns," "only one image." Below that, the enrichment actions are ranked by score recovery: the number of points your overall score would gain if you closed that gap.
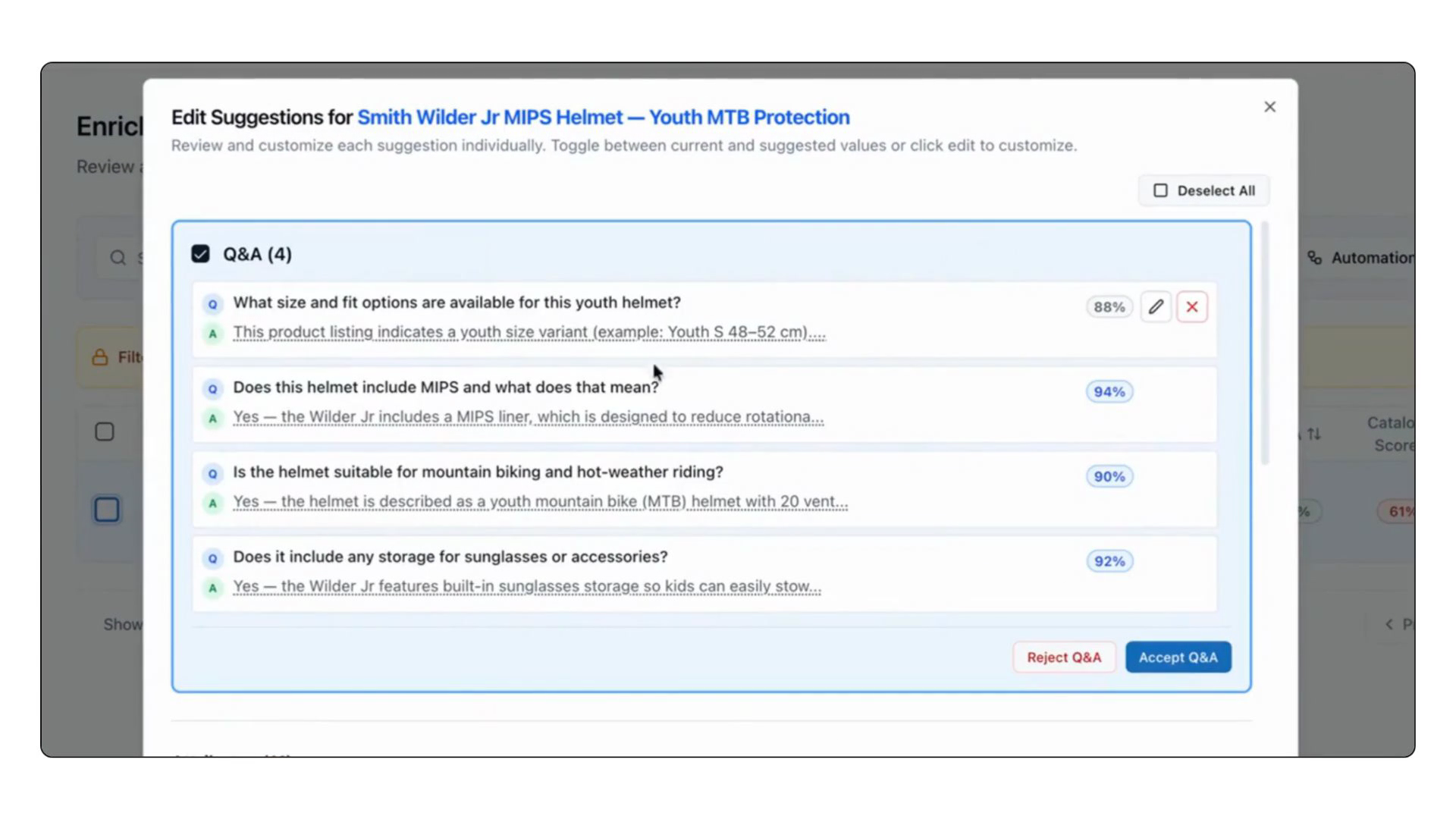
That ranking is the important part. The top recommendation isn't the lowest-scoring dimension, it's the highest-leverage one. A 0/3 on a dimension worth 7 points matters less than a 1/3 on a dimension worth 20. Catalog Scoring does that math for you, so your team works the list top-down and raises the score fastest, instead of guessing which fix was worth the effort.
.gif?width=640&height=324&name=Catalog%20Scoring_final%20(1).gif)
Catalog Scoring is event-driven. A product re-scores when it's added or updated, when you apply an enrichment suggestion to it, or when you click Re-score. There's no nightly batch to wait on. The practical effect: you can fix data in the enrichment queue and watch the score move within minutes. Thus you can change, measure, confirm, in the same sitting. The work you do and the number that proves it are connected directly, and show effect within a reporting cycle.
A quality score is only useful if you can trust and reproduce it. So we split the work. The language model does the judgment: it reads each product, evaluates each of the seven dimensions, and lists the specific gaps. But it does none of the arithmetic. The weighted sum, the readiness bands, and the priority ranking are all deterministic backend code. The same product data produces the same score every time, and the methodology is versioned, so a number you take into a leadership review holds up to scrutiny. (Because weights are fixed per methodology version, scores are directly comparable within the same version.)
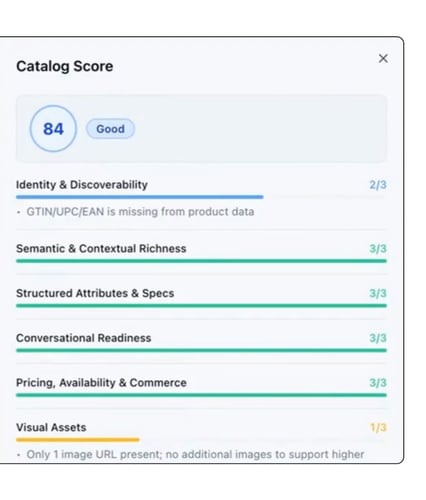
A few honest boundaries. Catalog Scoring measures how ready your data is; it does not control or guarantee whether any engine recommends a product, and it isn't "AI SEO." It scores the catalog payload — source data plus accepted enrichments — not your live product page, your outbound feed, or how you're represented at each retailer. And it surfaces gaps, it doesn't change your data. Accepting an enrichment is always a separate, reviewed action.
Catalog Scoring shows up in three places: a sortable RFB Catalog column in your Products list (sort by it to find your weakest products fast), a score chip on each product's detail page, and a portfolio-level score on your dashboard so you can track the whole catalog over time.
Catalog Scoring is the first dimension in a broader Product Scoring effort. It scores the catalog data you control today; ahead, the same approach will extend to the live product page, the outbound feed, and how each product is represented at the retailers you sell through. Agentic Commerce Optimization starts with measurement — you can't prioritize what you can't score. This is where that measurement begins.
Catalog Scoring is live now. Open any product to see its score. Or sign up for a demo to see how your products fare across answer engines right now.
A new Deloitte Digital study surveyed both sides of the counter and found a wide gap: brands believe they deliver good commerce experiences, and...
New benchmark adds an agentic readiness layer to the Top 1000, revealing which retailers are positioned to compete as AI shopping agents reshape...